Одна из основных проблем, которая возникает при дополнении обычной семантической сети новыми фактами, связана с квантованием.
Хендрикс предложил метод, названный разделением семантической сети, и ввёл понятие иерархически упорядоченного множества пространств, определяющих границы действия вершин экземпляров.
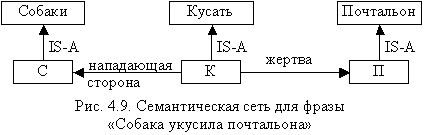 |
Например: “Собака укусила почтальона”. “Собака”, ”укус”, “почтальон” – классы. Если ввести вершины переменных, отображающие специальные понятия в виде экземпляров “с”, “к”, “п”, то можно построить сеть (рис. 4.9).
С помощью этой сети можно представить факт “Каждая собака кусает почтальона”:
» собака (x) ($ y почтальон (y) / кусать(x,y)).
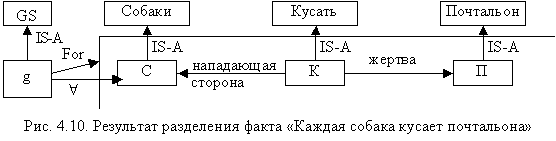 |
Результат разделения этого факта можно представить в виде сети (рис. 4.10).
Вершина g эквивалентна “каждая собака …”, GS – » x собака(x), следовательно, g – экземпляр GS.
Экземпляр GS имеет два атрибута: Form – указывает утверждение, которое нужно сделать; » – квантор всеобщности. Другие переменные “к” и “п”, разделённые отношением Form, ограничены лишь квантором существования ($ ).
4.5. Получение вывода с помощью семантической сети
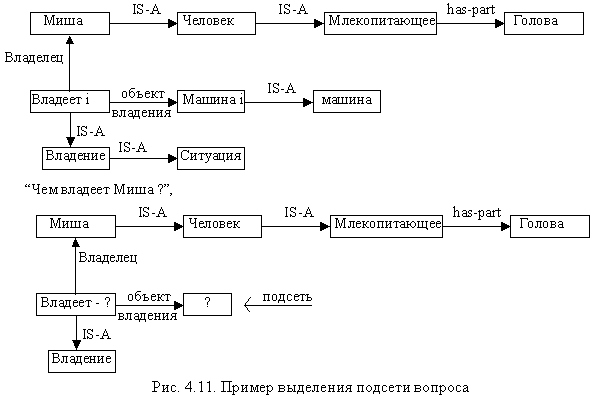 Особенность семантической сети заключается в целостности системы, выполненной на её основе, не позволяющей иметь базы знаний и модели вывода. Интерпретация семантической сети определяется с помощью использующих её процедур. Эти процедуры основаны на нескольких способах, но наиболее типичный – способ сопоставления частей сетевой структуры. Он основан на построении подсети, соответствующей вопросу, и сопоставлении ее с базой данных сети. При этом для исчерпывающего сопоставления с базой данных вершинам переменных подсети присваиваются гипотетические знания (рис. 4.11).
Особенность семантической сети заключается в целостности системы, выполненной на её основе, не позволяющей иметь базы знаний и модели вывода. Интерпретация семантической сети определяется с помощью использующих её процедур. Эти процедуры основаны на нескольких способах, но наиболее типичный – способ сопоставления частей сетевой структуры. Он основан на построении подсети, соответствующей вопросу, и сопоставлении ее с базой данных сети. При этом для исчерпывающего сопоставления с базой данных вершинам переменных подсети присваиваются гипотетические знания (рис. 4.11).
Процесс сопоставления:
1) отыскивается вершина “владеть”, имеющая ветвь “владелец”, направленная к вершине “Миша”;
2) соединение с вершиной, которая показывает ветвь “собственность”;
3) ответ на вопрос.
Процесс вывода (рис. 4.12):
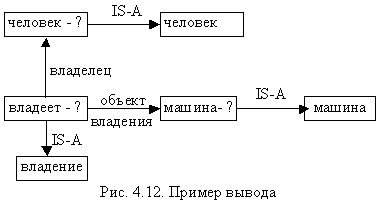 |
“Существует ли человек, который владеет машиной”
Однако эта подсеть не годится для непосредственного сопоставления с базой данных. Из узла “Миша” к узлу “человек” проводится дуга “IS-A” (означающая, что Миша
является человеком). После этого становится возможным соединение «владеть?» с «владеет I» и «машина?» с «машина I» и проведение сопоставления. В результате ответ на вопрос звучит как «Да – это Миша».
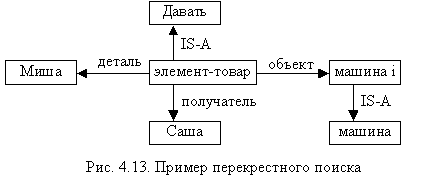 |
Перекрёстный поиск (один из способов вывода) – поиск отношений между объектами и ответ на вопрос путём обнаружения узла, в котором имеются дуги, идущие от двух разных узлов (рис. 4.13).
Вопрос: Какие деловые отношения между Мишей и Сашей?
Ответ: Миша отдал эту машину Саше.