В любых средствах отображения информация представляется информационной моделью (ИМ) — организованным в соответствии с определенной системой правил отображением состояний объекта управления, внешней среды и способов воздействия на них. Представление физического состояния одной системы физическим состоянием другой называется кодированием. В ИМ в закодированной форме представляется сущность реальных процессов, явлений, объектов. Так как информационная модель отражает только наиболее существенные для данной цели управления параметры объекта, то один и тот же объект можно представить различными моделями: для авиапассажира существенными являются пункт назначения, номер рейса, время отправления и прибытия, тип самолета (все эти параметры могут быть представлены на информационно-справочном табло аэровокзала информационной моделью в виде буквенно-цифрового текста); для пилотов сущность полета должна отражаться совокупностью показаний приборов, характеризующих работу схем систем самолета и его положение в пространстве (эти показания представляют в форме, обеспечивающей оптимальное восприятие большого объема информации и переработку ее в короткое время); для диспетчера, управляющего взлетом и посадкой, существенным является пространственное положение самолета в зоне аэродрома, его скорость, высота, направление движения (на ситуационном экране диспетчерского пункта все самолеты в зоне аэродрома изображаются движущимися точками или условными знаками, рядом с которыми в цифровой форме указываются требуемые параметры).
Кодирование информации в ИМ осуществляется с помощью элементов информационной модели, в качестве которых используются буквы, условные знаки (символы), геометрические фигуры, линии, точки и т. д. Набор используемых элементов ИМ составляет алфавит информационной модели. Число элементов, образующих алфавит, называют основанием кода алфавита Na. В состав алфавита могут включаться и такие признаки элементов, как цвет, градации яркости, размер, ориентация и др.
Часть пространства, в пределах которого происходит формирование информационной модели, называется информационным полем (ИП).
Отношение ширины информационного поля В к его высоте Н называется форматом информационного поля ![]() .
.
По используемому алфавиту выделяют следующие основные типы информационных моделей: буквенно-цифровые, графические, полутоновые, комбинированные.
В буквенно-цифровых моделях в качестве элемента ИМ используются буквы, цифры, условные знаки (символы), а свойства отображаемого объекта или процесса представляются в виде буквенного текста, цифровой комбинации, формул, таблиц. При построении буквенно-цифровой ИМ все информационное поле разбивается на отдельные знакоместа.
Часть информационного поля, необходимая и достаточная для изображения одного знака в виде буквы, цифры, символа, называется знакоместом.
Множество элементов информационной модели образуется из множества элементов отображения.
Простейший элемент информационной модели, который может быть реализован выбранным типом индикатора, называется элементом отображения (ЭО). ЭО характеризуется формой, геометрическими размерами, яркостью, временем послесвечения,
цветом и т.д. Элементами отображения могут быть: контуры знаков, выполненные конструктивно как простейшие элементы (например, цифры, нанесенные на поверхность барабана счетчика электрической энергии, или буквы рекламы); сегменты — протяженные конструкции, площадь которых ограничена прямыми линиями или кривыми второго порядка (например, сегменты цифр электронных наручных часов); точечные элементы (например, точечный элемент информационно-справочных табло).
В соответствии с используемыми элементами отображения все способы формирования знаков можно разделить на две основные группы:
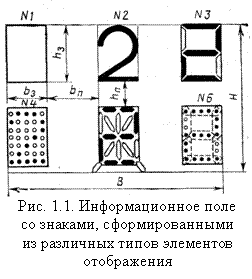 1) знакомоделирующий способ характеризуется целостным представлением знака, при этом форма элемента отображения совпадает с контуром знака, например цифры 2 в знакоместе № 2 (рис. 1.1);
1) знакомоделирующий способ характеризуется целостным представлением знака, при этом форма элемента отображения совпадает с контуром знака, например цифры 2 в знакоместе № 2 (рис. 1.1);
2) знакосинтезирующий способ характеризуется тем, что знаки формируются из более простых элементов отображения. В знакоместе № 3 показан синтез цифры 2 из сегментов. Набор сегментов в знакоместе составляет некоторую обобщенную фигуру – полиграмму. Из 7-сегментной полиграммы, представленной на рис. 1.1, можно синтезировать все арабские цифры и некоторые буквы (Н, Р, Е и др.). Расширение алфавита достигается за счет увеличения числа сегментов в полиграмме.
В знакоместе № 5 показана 18-сегментная полиграмма, позволяющая синтезировать буквы русского и латинского алфавитов. В знакоместе № 4 показан синтез той же цифры 2 из точечных ЭО. К точечным элементам отображения относят такие ЭО, размеры которых намного меньше размеров синтезируемых знаков (hэ < hз; bэ < bз). В пределах знакоместа точечные ЭО образуют матрицу знака. Число элементов отображения в матрице знаков выбирают, исходя из требования безошибочной и быстрой идентификации (опознавания) всех знаков алфавита. Так, например, матрица 5×7 (5 столбцов и 7 строк) в знакоместе № 4 (рис. 1.1) является практически минимально приемлемой для синтеза букв русского и латинского алфавитов и цифр. Для синтеза только арабских цифр размерность матрицы можно уменьшить до 3×5. Как показали психофизиологические исследования при опознавании символов, синтезированных с помощью матрицы 5×7, возможны ошибки. Так, например, часто путают В и 8; R и S; Q и О и др. Это делает целесообразным использование матриц с увеличенным числом точек, например 7×9. Дальнейшее увеличение числа этих точек, например до 9×13, к существенному улучшению восприятия не приводит.
В ряде случаев знаки синтезируются из укрупненных элементов, составленных из более простых элементов отображения. Например, на рис. 1.1 в знакоместе № 6 показана цифра 2, синтезированная из укрупненных элементов (сегментов), составленных из точечных ЭО.
Элементы отображения могут выполняться в виде отдельных конструктивных элементов, например электрической лампы накаливания, светодиода, катода газоразрядной лампы, выполненного в форме цифры или сегмента. Такие элементы отображения называются дискретными ЭО. В электронно-лучевых приборах элементы отображения, входящие в знак, генерируются электронным лучом в процессе воспроизведения изображения. Синтез знаков из полученных таким образом элементов называют знакогенерирующим способом формирования знаков.
Графические информационные модели (ГИМ) представляют чертежами, диаграммами, схемами (структурными, функциональными, монтажными) и т. д. Основными
элементами информационной модели при построении графической ИМ являются линии, точки, двумерные области. Наиболее универсальными элементами отображения, из которых формируются элементы ГИМ, являются точечные ЭО. Каждый точечный ЭО, входящий в формируемую модель, должен быть задан координатами Xi; Yi, определяющими его положение на информационном поле.
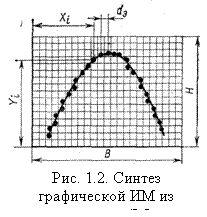
На рис. 1.2 показана кривая, синтезированная из точечных элементов отображения. Синтез из отдельных ЭО приводит к дискретизации изображения. Абсолютное значение погрешности дискретизации лежит в пределах ± 1/2 dЭ (dЭ – шаг квантования, определяемый как расстояние между центрами точечного ЭО). Следовательно, для уменьшения погрешности дискретизации необходимо уменьшить величину dЭ, прежде всего размер самого ЭО. Глаз не замечает дискретного характера изображения, если угловой размер ЭО близок к предельному углу, под которым человек различает две раздельные точки. Уменьшение размеров ЭО при сохранении размеров информационного поля приводит к увеличению общего числа ЭО и соответственно к техническому усложнению средств отображения информации.
 Для упрощения графических средств отображения информации (СОИ) при синтезе ГИМ часто используют укрупненные графические элементы – графемы. В зависимости от характера ГИМ в качестве графических элементов могут быть использованы отрезки прямых, дуги различной кривизны, двумерные фигуры. Синтез графической информационной модели с помощью графем заключается в разбиении ГИМ на отдельные фрагменты с последующим подбором графических элементов, наиболее точно аппроксимирующих выделенный фрагмент. В частном случае при использовании в качестве графем отрезков прямых полученная ГИМ представлена кусочно-линейной аппроксимацией. Выделение фрагментов ГИМ осуществляется путем разбиения информационного поля на графические знакоместа. Большей частью положение графического знакоместа совмещают с положением буквенно-цифрового. В этом случае для обеспечения слитности графического изображения размеры графического знакоместа bЗГ и hЗГ увеличивают на величину интервала между знакоместами hП и между текстовыми строками hГ (bЗГ = bЗ + bП , hЗГ = hЗ + hП). Совмещение графических и буквенно-цифровых знакомест позволяет сохранить общую структуру СОИ для формирования двух типов ИМ. Графема часто является укрупненным элементом отображения, формируемым из точечных ЭО. Таким образом, при синтезе ГИМ с помощью графем возникает погрешность аппроксимации фрагмента информационной модели графическим элементом в пределах знакоместа, а также погрешность, связанная с искажением самой графемы из-за дискретного характера ее формирования.
Для упрощения графических средств отображения информации (СОИ) при синтезе ГИМ часто используют укрупненные графические элементы – графемы. В зависимости от характера ГИМ в качестве графических элементов могут быть использованы отрезки прямых, дуги различной кривизны, двумерные фигуры. Синтез графической информационной модели с помощью графем заключается в разбиении ГИМ на отдельные фрагменты с последующим подбором графических элементов, наиболее точно аппроксимирующих выделенный фрагмент. В частном случае при использовании в качестве графем отрезков прямых полученная ГИМ представлена кусочно-линейной аппроксимацией. Выделение фрагментов ГИМ осуществляется путем разбиения информационного поля на графические знакоместа. Большей частью положение графического знакоместа совмещают с положением буквенно-цифрового. В этом случае для обеспечения слитности графического изображения размеры графического знакоместа bЗГ и hЗГ увеличивают на величину интервала между знакоместами hП и между текстовыми строками hГ (bЗГ = bЗ + bП , hЗГ = hЗ + hП). Совмещение графических и буквенно-цифровых знакомест позволяет сохранить общую структуру СОИ для формирования двух типов ИМ. Графема часто является укрупненным элементом отображения, формируемым из точечных ЭО. Таким образом, при синтезе ГИМ с помощью графем возникает погрешность аппроксимации фрагмента информационной модели графическим элементом в пределах знакоместа, а также погрешность, связанная с искажением самой графемы из-за дискретного характера ее формирования.