Каждая вычислительная машина имеет свой собственный язык программирования – язык команд или машинный язык – и может исполнять программы, записанные только на этом языке. С помощью машинного языка, в принципе, можно описать любой алгоритм, но затраты на программирование будут чрезвычайно велики. Это обусловлено тем, что машинный язык позволяет описывать и обрабатывать лишь примитивные структуры данных – бит, байт, слово. Программирование в машинных кодах требует чрезмерной детализации программы и доступно лишь программистам, хорошо знающим устройство и функционирование ЭВМ. Преодолеть эту трудность и позволили языки высокого уровня (Фортран, ПЛ/1, Паскаль, Си, Ада и др.) с развитыми структурами данных и средствами их обработки, не зависящими от языка конкретной ЭВМ.
Алгоритмические языки высокого уровня дают возможность программисту достаточно просто и удобно описывать алгоритмы решения многих прикладных задач. Такое описание называют исходной программой, а язык высокого уровня — входным языком.
Языковым процессором называют программу на машинном языке, позволяющую вычислительной машине понимать и выполнять программы на входном языке. Различают два основных типа языковых процессоров: интерпретаторы и трансляторы.
Интерпретатор – это программа, которая в качестве входа допускает программу на входном языке и по мере распознавания конструкций входного языка реализует их, выдавая на выходе результаты вычислений, предписанные исходной программой.
Транслятор – это программа, которая допускает на входе исходную программу и порождает на своем выходе программу, функционально-эквивалентную исходной, называемую объектной. Объектная программа записывается на объектном языке. В частном случае, объектным языком может служить машинный язык, и в этом случае, полученную на выходе транслятора программу можно сразу же выполнить на ЭВМ (проинтерпретировать). При этом ЭВМ является интерпретатором объектной программы в машинных кодах. В общем случае объектный язык не обязательно должен быть машинным или близким к нему (автокодом). В качестве объектного языка может служить некоторый промежуточный язык – язык, лежащий между входным и машинным языками.
Если в качестве объектного языка используется промежуточный язык, то возможны два варианта построения транслятора.
• Первый вариант – для промежуточного языка имеется (или разрабатывается) другой транслятор с промежуточного языка на машинный, и он используется в качестве последнего блока проектируемого транслятора.
• Второй вариант построения транслятора с использованием промежуточного языка – построить интерпретатор команд промежуточного языка и использовать его в качестве последнего блока транслятора. Преимущество интерпретаторов проявляется в отладочных и диалоговых трансляторах, обеспечивающих работу пользователя в диалоговом режиме, вплоть до внесений изменений в программу без ее повторной полной перетрансляции.
Интерпретаторы используются также и при эмуляции программ – исполнении на технологической машине программ, составленных для другой (объектной) машины. Данный вариант, в частности, используется при отладке на универсальной ЭВМ программ, которые будут выполняться на специализированной ЭВМ.
Транслятор, использующий в качестве входного языка язык, близкий к машинному (автокод или ассемблер), традиционно называют ассемблером. Транслятор для языка высокого уровня называют компилятором.
В построении компилятора за последние годы достигнуты значительные успехи. Первые компиляторы использовали так называемые прямые методы трансляции – это преимущественно эвристические методы, в которых на основе общей идеи для каждой конструкции языка разрабатывался свой алгоритм перевода в машинный эквивалент. Эти методы были медленные и не носили структурного характера.
В основе методики проектирования современных компиляторов лежит композиционный синтаксически-управляемый метод обработки языков. Композиционный в том смысле, что процесс перевода исходной программы в объектную реализуется композицией функционально независимых отображений с явно выделенными входными и выходными структурами данных. Отображения эти строятся из рассмотрения исходной программы, как композиции основных аспектов (уровней) описания входного языка: лексики, синтаксиса, семантики и прагматики, и выявления этих аспектов из исходной программы в ходе ее компиляции. Рассмотрим эти аспекты с целью получения упрощенной модели компилятора.
Основой любого естественного или искусственного языка является алфавит – набор допустимых в языке элементарных знаков (букв, цифр и служебных знаков). Знаки могут объединяться в слова – элементарные конструкции языка, рассматриваемые в тексте (программе) как неделимые символы, имеющие определенный смысл. Словом может быть и одиночный символ. Например, в языке Паскаль словами являются идентификаторы, ключевые слова, константы, и разделители, в частности знаки арифметических и логических операций, скобки, запятые и другие символы. Словарный состав языка вместе с описанием способов их представления составляют лексику языка.
Слова в языке объединяются в более сложные конструкции – предложения. В языках программирования простейшим предложением является оператор. Предложения строятся из слов и более простых предложений по правилам синтаксиса. Синтаксис языка представляет собой описание правильных предложений. Описание смысла предложений, т.е. значений слов и их внутренних связей, составляет семантику языка. В дополнение отметим, что конкретная программа несет в себе некоторое воздействие на транслятор – прагматизм. В совокупности синтаксис, семантика и прагматизм языка образуют семиотику языка.
Перевод программы с одного языка на другой, в общем случае состоит в изменении алфавита, лексики и синтаксиса языка программы с сохранением ее семантики. Процесс трансляции исходной программы в объектную обычно разбивается на несколько независимых подпроцессов (фаз трансляции), которые реализуются соответствующими блоками транслятора. Удобно считать основными фазами трансляции лексический анализ, синтаксический анализ, семантический анализ и
синтез объектной программы. Тем не менее, во многих реальных компиляторах эти фазы разбиваются на несколько подфаз, могут также быть и другие фазы (например, оптимизация объектного кода). На рис. 1.1 показана упрощенная функциональная модель транслятора.
В соответствии с этой моделью входная программа, прежде всего, подвергается лексической обработке. Цель лексического анализа – перевод исходной программы на внутренний язык компилятора, в котором ключевые слова, идентификаторы, метки и константы приведены к одному формату и заменены условными кодами: числовыми или символьными, которые называются дескрипторами. Каждый дескриптор состоит из двух частей: класса (типа) лексемы и указателя на адрес в памяти, где хранится информация о конкретной лексеме. Обычно эта информация организуется в виде таблиц. Одновременно с переводом исходной программы на внутренний язык на этапе лексического анализа проводится лексический контроль - выявление в программе недопустимых слов.
Синтаксический анализатор воспринимает выход лексического анализатора и переводит последовательность образов лексем в форму промежуточной программы. Промежуточная программа является, по существу, представлением синтаксического дерева программы. Последнее отражает структуру исходной программы, т.е. порядок и связи между ее операторами. В ходе построения синтаксического дерева выполняется синтаксический контроль – выявление синтаксических ошибок в программе.
Фактическим выходом синтаксического анализа может быть последовательность команд, необходимых для того, чтобы строить промежуточную программу, обращаться к таблицам справочника, выдавать, когда это требуется, диагностическое сообщение.
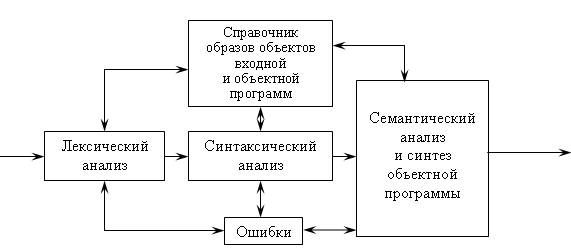
Рис. 1.1. Упрощенная функциональная модель транслятора
Синтез объектной программы начинается, как правило, с распределения и выделения памяти для основных программных объектов. Затем производится исследование каждого предложения исходной программы и генерируется семантически эквивалентные предложения объектного языка. В качестве входной информации здесь используется синтаксическое дерево программы и выходные таблицы лексического анализатора – таблица идентификаторов, таблица констант и другие. Анализ дерева позволяет выявить последовательность генерируемых команд объектной программы, а по таблице идентификаторов определяются типы команд, которые допустимы для значений операндов в генерируемых командах (например, какие требуется породить команды: с фиксированной или плавающей точкой и т.д.).
Непосредственно генерации объектной программы часто предшествует семантический анализ, который включает различные виды семантической обработки. Один из видов – проверка семантических соглашений в программе. Примеры таких соглашений: единственность описания каждого идентификатора в программе, определение переменной производится до ее использования и т.д. Семантический анализ может выполняться на более поздних фазах трансляции, например, на фазе оптимизации программы, которая тоже может включаться в транслятор. Цель оптимизации – сокращение временных ресурсов или ресурсов оперативной памяти, требуемых для выполнения объектной программы.
Таковы основные аспекты процесса трансляции с языков высокого уровня. Подробнее организация различных фаз трансляции и связанные с ними практические способы их математического описания рассматриваются ниже.