Контекстно-свободные грамматики традиционно служат основой для синтаксического анализа компиляции. Описание входного языка включает правила синтаксиса, в соответствии с которыми порождаются тексты программ. Каждому синтаксическому правилу в КС-грамматике соответствует правило вывода (продукция) грамматики. Поэтому последовательность правил вывода грамматики, которые применяются для порождения текста программы, определяет ее структуру. Выводов некоторой цепочки w в грамматике G в общем случае может быть достаточно много. Это происходит в силу того, что если некоторая промежуточная цепочка вывода содержит более чем одно вхождение нетерминального символа, то правила подстановки могут применяться, в принципе, к любому вхождению нетерминального символа. Если изменить лишь порядок применения правил, а сами правила будут использоваться те же, то, очевидно, будет получен другой вывод, но заключительная терминальная цепочка и ее определяемая выводом синтаксическая структура останутся неизменными. Обычно множество выводов КС-грамматики ограничивается, и рассматриваются не все ее возможные выводы, а лишь так называемые левосторонние или правосторонние выводы.
Определение 3.1.1. Вывод в КС-грамматике называют левосторонним (правосторонним), если правила вывода применяются к самому левому (правому) вхождению нетерминального символа каждой цепочки вывода.
Пример 3.1.1. Рассмотрим КС-грамматику G = <N, Т, Р, S>, у которой
N = {E,R,F},T = {i,+,*,),(},S = {E},
Р = { 1. Е ![]() E+R
E+R
2. E ![]() R
R
3. R ![]() R*F
R*F
4. R ![]() F
F
5. F ![]() (E)
(E)
6. F ![]() i}.
i}.
Данная КС-грамматика порождает арифметические выражения, построенные из идентификаторов (в грамматике идентификатору соответствует терминальный символ i), знаков арифметических операций + и *, скобок ( и).
Для терминальной цепочки i+i*i построим ее левосторонний и правосторонний выводы:
а) левосторонний вывод:
1 2 4 6 3 4 6 6
E ![]() E+R
E+R ![]() R+R
R+R ![]() F+R
F+R ![]() i+R
i+R ![]() i+R*F
i+R*F ![]() i+F*F
i+F*F ![]() i+i*F
i+i*F ![]() i+i*i.
i+i*i.
б) правосторонний вывод:
1 3 6 4 6 2 4 6
E ![]() E+R
E+R ![]() E+R*F
E+R*F ![]() E+R*i
E+R*i ![]() E+F*i
E+F*i ![]() E+i*i
E+i*i ![]() R+i*i
R+i*i ![]() F+i*i
F+i*i ![]() i+i*i.
i+i*i.
Получение синтаксической структуры программы в форме шагов вывода не совсем удобно — в выводе не просматривается явно структура программы. Более наглядным является представление структуры программы в виде дерева вывода (дерева синтаксического разбора).
Под деревом синтаксического разбора будем понимать конечный неориентированный граф, обладающий свойствами[6]:
· у него имеется одна вершина, в которую не входит ни одна дуга; эту вершину будем называть корнем дерева, корень дерева соответствует начальному символу грамматики — аксиоме;
· в каждую из его остальных вершин входит лишь одна дуга; вершины, не имеющие выходящих из них дуг, называются заключительными вершинами дерева или листьями, в КС-грамматике им соответствуют терминальные символы грамматики; не заключительным вершинам дерева соответствуют нетерминальные символы грамматики;
· он не содержит контуров.
Более формально, дерево разбора в КС-грамматике G = <N, Т, Р, S> — это упорядоченное дерево, каждая вершина которого помечена символом X![]() Т
Т ![]() N.
N.
Если внутренняя вершина помечена символом А, а ее прямые потомки — символами X1, X2, …, Хr, то А ![]() Х1, Х2, …, Хr — правило грамматики G. Построение синтаксического дерева Dn по выводу S =
Х1, Х2, …, Хr — правило грамматики G. Построение синтаксического дерева Dn по выводу S = ![]() 0,
0, ![]() 1,…,
1,…,![]() n осуществляется следующим образом:
n осуществляется следующим образом:
1) при m = 0 D0 состоит из одной вершины, помеченной символом S – аксиома грамматики G;
2) пусть при 0![]() m
m![]() n для вывода S =
n для вывода S = ![]() 0,
0, ![]() 1,…,
1,…,![]() n построено дерево Dm и
n построено дерево Dm и ![]() m = = x1Ax2,
m = = x1Ax2, ![]() m+1 = x1
m+1 = x1![]() x2, и А
x2, и А ![]()
![]() — правило из Р,
— правило из Р, ![]() = X1X2…Xr. В дереве Dm символы цепочки
= X1X2…Xr. В дереве Dm символы цепочки ![]() m являются метками его листьев, выписанных слева на право. Тогда дерево вывода Dm+1 с цепочкой листьев
m являются метками его листьев, выписанных слева на право. Тогда дерево вывода Dm+1 с цепочкой листьев ![]() m+1 строиться путем добавления новых листьев с метками X1, X2, …, Xr и соответствующих ребер;
m+1 строиться путем добавления новых листьев с метками X1, X2, …, Xr и соответствующих ребер;
3) дерево Dn – искомое дерево для вывода S = ![]() 0,
0, ![]() 1,…,
1,…,![]() n.
n.
В случае полного вывода цепочка ![]() n состоит из терминальных символов, поэтому ни вывод, ни дальнейшие построения дерева вывода не возможны.
n состоит из терминальных символов, поэтому ни вывод, ни дальнейшие построения дерева вывода не возможны.
На рис. 3.1. показано дерево синтаксического разбора цепочки i+i*i для грамматики из примера 3.1.1. Левостороннему выводу цепочки соответствует обход ее дерева вывода сверху вниз и слева направо. Аналогично определяется и правосторонний вывод, только ориентацию пути обхода дерева необходимо поменять на обратную.
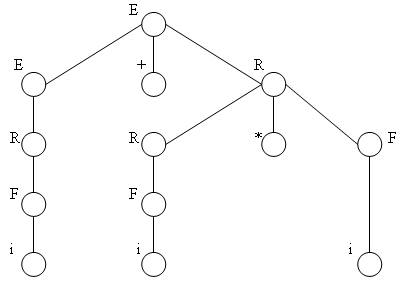
Рис. 3.1. Дерево синтаксического разбора цепочки i+i*i для грамматики из примера 3.1.1
Определение 3.1.2. КС-грамматика называется однозначной, если для некоторой цепочки ![]()
![]() (N
(N![]() Т)+ существует только одно дерево вывода. В противном случае грамматика называется неоднозначной.
Т)+ существует только одно дерево вывода. В противном случае грамматика называется неоднозначной.
Необходимо отметить, что однозначность или неоднозначность, это свойство грамматики G, а не языка L(G). В общем случае один и тот же язык можно описать с помощью бесконечного множества порождающих его грамматик. Для практических целей имеет смысл рассматривать лишь однозначные грамматики, которые обеспечивают однозначную семантическую интерпретацию программы и соответственно получение машинной программы.
Например, для языка арифметических выражений из примера 3.1.1. грамматика с правилами Е ![]() Е+Е | Е*Е | i неоднозначна, так как цепочка i+i*i имеет два дерева вывода (рис. 3.2.).
Е+Е | Е*Е | i неоднозначна, так как цепочка i+i*i имеет два дерева вывода (рис. 3.2.).
Поэтому такая грамматика не может служить основой для выполнения синтаксического анализа.
Определение 3.1.3. КС-грамматика G называется:
а) леворекурсивной, если в ней имеются выводы вида
X![]() X
X![]() , где X
, где X![]() N,
N, ![]()
![]() V+;
V+;
б) праворекурсивной, если в ней имеются выводы вида
X![]()
![]() X, где X
X, где X![]() N,
N, ![]()
![]() V+;
V+;
в) самовставляющей, если она имеет выводы вида
X![]()
![]() X
X![]() , где X
, где X![]() N и
N и ![]() ,
,![]()
![]() V+.
V+.
КС -грамматика G называется рекурсивной, если имеет место хотя бы один из случаев а) — в).
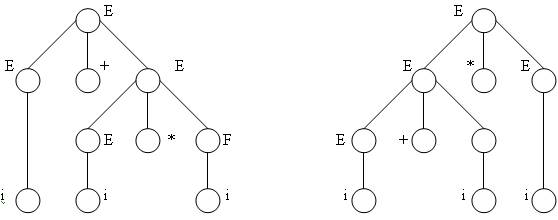
Рис. 3.2. Неоднозначные деревья вывода
В общем случае любая КС-грамматика, описывающая язык программирования, является рекурсивной. Важным является выявление вида рекурсии при использовании того или иного метода синтаксического разбора. Различные методы построения дерева синтаксического разбора допускают в грамматике, как правило, лишь один вид рекурсии. Задачу синтаксического разбора можно сформулировать следующим образом: для заданного предложения a1, a2…an ![]() T и грамматики G построить треугольник и попытаться заполнить его внутреннюю часть деревом синтаксического разбора [13]:
T и грамматики G построить треугольник и попытаться заполнить его внутреннюю часть деревом синтаксического разбора [13]:
В принципе, не имеет значения то, каким образом будет заполняться внутренняя часть треугольника. На рис. 3.3. изображены три наиболее используемых способа заполнения треугольника.
Стратегия синтаксического разбора, изображенная на рис. 3.3, а называется разбором сверху вниз. Так как программа может состоять из многих тысяч предложений, методы, требующие размещения в оперативной памяти всего предложения в общем случае неприемлемы. Поэтому на практике применяются методы, заполняющие треугольник, используя часть предложения. Очевидный способ разбора предложения по частям — перебирать слова по одному слева направо в их естественной последовательности. При этом используются две основные стратегии заполнения треугольника разбора: сверху вниз и слева направо (рис. 3.3, б) или снизу вверх и слева направо (рис. 3.3, в).
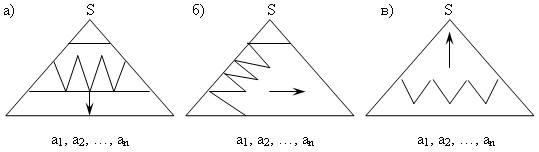
Рис. 3.3. Основные способы построения синтаксического дерева
Выбор стратегии синтаксического разбора для конкретной КС-грамматики, в общем случае, обуславливает быстроту его выполнения. В настоящее время разработано и используется на практике большое количество алгоритмов разбора. Каждый из них использует ту или иную стратегию разбора и в большинстве случаев накладывает различные ограничения на правила КС-грамматик, т.е. исходная КС-грамматика, прежде чем она может быть использована в качестве основы синтаксического разбора, должна быть подвергнута определенным преобразованиям. Эти преобразования в конечном итоге обеспечивают:
· однозначность, детерминированность грамматического разбора;
· устраняют лишние шаги в дереве разбора;
· простые эмпирические критерии выбора продукции из множества альтернативных.
Ниже будут рассмотрены такие преобразования КС-грамматик, которые не затрагивают главного — способности порождать преобразованной КС-грамматикой того же языка, что и исходная КС-грамматика.