Метод восходящего синтаксического анализа (снизу вверх) состоит в том, что отталкиваясь от заданной цепочки пытаются привести ее к начальному символу (аксиоме грамматики), т.е. восходя от листьев, построить дерево синтаксического анализа.
Рассмотрим общие принципы работы детерминированного восходящего синтаксического анализатора. Для заданной входной цепочки восходящий МП-автомат моделирует ее правый вывод в обратном порядке, т.е. правила грамматики применяются справа налево, и манипулирует своими магазинными и текущими входными символами с помощью операций переноса и свертки.
Операция переноса — это операция, которая вталкивает в магазин некоторый символ, соответствующий текущему входному символу и сдвигает вход, т.е. переносит со входа в магазин текущий символ.
Операция свертки, для некоторого правила р с r символами в правой части — это операция, которая выбирается только тогда, когда r верхних символов магазина представляют правую часть правила р. Операция свертки выталкивает из магазина верхние r символов и вталкивает туда символ, соответствующий левой части правила р.
Пример 3.4.1. Пусть задана грамматика G = <N, T, P, S>, у которой
N = <S, L, I>, T = {i, , , real}, S = {S},
P = { 1. S ![]() real L
real L
2. L ![]() L, I
L, I
3. L ![]() I
I
4. I ![]() i }
i }
и входная цепочка real i, i.
Правый вывод этой цепочки в грамматике G имеет вид:
1 2 4 3 4
S![]() real L
real L![]() real L, I
real L, I![]() real L, i
real L, i![]() real I, i
real I, i![]() real i, i
real i, i
Прослеживание полученного правого вывода в обратном порядке можно интерпретировать как построение дерева вывода.
При этом на каждом шаге вхождение правой части некоторого правила заменяется нетерминалом из левой части этого правила (рис. 3.6).
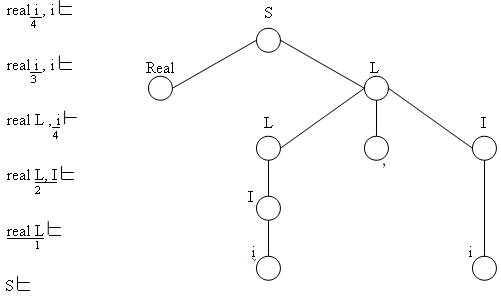
Рис. 3.6. Обращение правого вывода примера 3.4.1
Каждую подчеркнутую подцепочку называют «основой» цепочки, в которой она встречается.
Основа цепочки, состоящей из терминалов и нетерминалов, — это вхождение правой части последнего правила, примененного в правом выводе этой цепочки.
При моделировании обратного правого вывода с помощью МП-автомата осуществляется ПЕРЕНОС входных символов из входной ленты в магазинную память до тех пор, пока на верхушке магазина не окажется основа цепочки, к которой затем и применяется операция СВЕРТКА, которая выполняет замену основы левой частью соответствующего правила.
Для приведенного выше примера правого вывода цепочки real i, i ![]()
![]() работа МП-автомата, моделирующего этот вывод, может быть описана в виде следующей последовательности конфигураций и выполняемых при этом команд МП-автомата:
работа МП-автомата, моделирующего этот вывод, может быть описана в виде следующей последовательности конфигураций и выполняемых при этом команд МП-автомата:
|
СОДЕРЖИМОЕ МАГАЗИНА |
СОДЕРЖИМОЕ ВХОДНОЙ ЛЕНТЫ |
ПРИМЕНЯЕМАЯ КОМАНДА |
|
# |
real i, i |
ПЕРЕНОС |
|
# real |
i, i |
ПЕРЕНОС |
|
# real i |
, i |
СВЕРТКА (4) |
|
# real I |
, i |
СВЕРТКА (3) |
|
# real L |
, i |
ПЕРЕНОС |
|
# real L, |
i |
ПЕРЕНОС |
|
# real L, i |
|
СВЕРТКА (4) |
|
# real L, I |
|
СВЕРТКА (2) |
|
# real L |
|
СВЕРТКА (1) |
|
# S |
|
ДОПУСТИТЬ |
Анализ данного описания показывает, что конкатенация содержимого магазина и входной ленты МП-автомата в каждом такте его работы однозначно соответствует промежуточным цепочкам, получаемым на соответствующих шагах правого вывода в КС-грамматике. При этом в силу того, что автомат является детерминированным, комбинация входного символа на ленте и символа на вершине магазина должны в
каждом такте работы МП-автомата однозначно инициировать выполнение одной из его команд: ПЕРЕНОС, ОТВЕРГНУТЬ, ДОПУСТИТЬ, или СВЕРТКА (k), где k — номер основывающей подстановки. Для нашего примера комбинация символа «i» в магазине и символа «,» или символа «![]()
![]() » во входной строке инициируют операцию МП-автомата СВЕРТКА (4).
» во входной строке инициируют операцию МП-автомата СВЕРТКА (4).
Возникает естественный вопрос: для любой ли КС-грамматики можно найти такие комбинации, если нет, то какими свойствами должна обладать КС- грамматика, чтобы это сделать и каким образом. К сожалению, общей процедуры, дающей ответ на поставленный вопрос, нет. И для каждой конкретной грамматики требуется более тонкий анализ ее правил, а то и структуры возможных в ней выводов. Существуют различные подходы к проведению такого анализа и, соответственно, построению управляющей таблицы МП-автомата.
Наиболее универсальный из них — это метод Кнута (LR(k)-метод) [9]. Название LR(k) означает, что детерминированный синтаксический анализатор читает входную цепочку слева (Left) и выдает ее правый (Right) анализ на основе уже прочитанной части входной цепочки (левый контекст) и фиксированного числа предварительно просматриваемых символов (максимум k). В принципе, любая из однозначных КС-грамматик может рассматриваться как LR(k)-грамматика, при этом k = 0, 1, …, n.
Однако на практике LR(k)-метод не получил широкого распространения из-за своей громоздкости. К тому же было доказано, что если для описания процесса порождения предложений некоторого языка построена КС-грамматика, которая является LR(k)-грамматикой, то этот же язык может порождаться и LR(1)-грамматикой (другое дело как построить эту грамматику!). Другими словами, все детерминировано разбираемые КС-языки могут разбираться LR(1)-методом, и в случае восходящего разбора увеличение k-числа предварительно просматриваемых символов не ведет к возможности детерминированного анализа большего числа языков. Это совершенно не похоже на LL методы разбора (детерминированный разбор сверху вниз), там LL(k) метод позволяет разобрать более широкий класс языков, чем например, LL(1) метод.
Оказалось также, что для описания синтаксиса языков программирования [9] бывает достаточно не только LR(1)-грамматик, а даже, так называемых, SLR(1)-грамматик. SLR(1)-грамматика — простая (simple) LR(l)-грамматика. SLR(l)-грамматика отличается от LR(l)-грамматик тем, что для определения конца основы в SLR(l)-грамматике используется только один предварительно просмотренный символ (как и в LR(1)), но никакого внимания не уделяется левому контексту (т.е. не учитывается уже обработанная часть цепочки), тогда как в более общем случае LR(1) метода левый контекст учитывается и даже играет решающую роль. Еще раз напомним, что речь идет не об описании работы МП-автомата, а о построении его управляющих таблиц, т.е. этапе анализа правил грамматики.
Существуют и другие подходы к построению детерминированного восходящего МП-автомата, но они применимы к более узким классам КС-грамматик. Наиболее известный из них — метод предшествования, применим он к так называемым грамматикам простого предшествования.
С позиций универсальности применения различных методов к построению детерминированного восходящего синтаксического анализатора для различных классов КС-грамматик, эти грамматики образуют иерархию грамматик. Эта иерархия показана на рис.3.7.
Детерминированные однозначные КС-языки
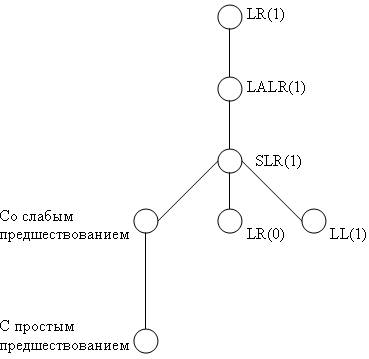
Рис 3.7. Иерархия грамматик
Не существует общей процедуры, которая бы могла определить, к какому классу относится та или иная КС-грамматика. Нельзя, например, решить, существует ли такое значение k, для которого заданная грамматика будет LR(k)-грамматикой. Но можно определить, обладает ли конкретная грамматика признаком LR(k) для заданного k. В частности, можно решить, является ли грамматика LR(0) или LR(1)-грамматикой. Либо можно выяснить, является ли данная КС-грамматика грамматикой простого предшествования и т.д. Выяснить это можно лишь путем применения конкретного метода построения синтаксического анализатора, т.е. например, если применяется метод предшествования, и в результате его применения построен анализатор по методу предшествования, то можно утверждать, что исходная КС-грамматика является грамматикой предшествования. Иерархия грамматик, показанная на рис. 3.6, отражает и сложность построения анализаторов того или иного типа. Более просто это выполняется для грамматик нижних уровней и менее тривиально для LR(1)-грамматик. Поэтому на практике обычно стараются воспользоваться менее сложным методом и лишь при неуспехе переходить к более универсальным. Эта стратегия применяется и в автоматических генераторах синтаксических анализаторов [9].