После выявления структуры программы транслятор должен выделить место в памяти машины для значений переменных, используемых в программе, и поместить соответствующие адреса в таблицу идентификаторов. Реализуется это в фазе распределения памяти. В современных трансляторах применяются различные схемы распределения памяти, которые в общем случае тесно связаны как с конкретной логической структурой данных языка программирования, так и с возможностями представления этих структур в памяти конкретной машины. Для построения механизма распределения памяти транслятором необходимо предварительно решить вопросы связанные:
· с представлением структур данных языка программирования в адресном пространстве машины (обычно в линейном адресном пространстве);
· организацией передачи данных между процедурами (блоками) программы;
· стратегией выделения, освобождения и учета памяти во время выполнения программы.
Уяснение всех этих вопросов возможно лишь при детальном описании исходного языка программирования. У нас нет такой возможности, поэтому остановимся лишь на общих подходах их решения.
Будем полагать, что язык программирования имеет структуру вложенных блоков и процедур, объединенных в рамках основной программы, которая тоже является процедурой, но без параметров. В языке допускается использование переменных различных типов: простые переменные, массивы, структуры и т.д. При этом в описании массива внутри блока (процедуры) в качестве индексов можно использовать переменные.
Эффективность обработки данных во время выполнения программы существенно зависит от выбора машинного представления данных языкового уровня. Рассмотрим возникающие здесь проблемы на примере представления в памяти машины двумерного массива. Существуют несколько способов размещения двумерного массива. Обычный способ — хранить его в области данных по строкам в порядке возрастания, т.е. для массива описанного, например в виде А(1 :М, 1 :N), каждый элемент которого занимает одну ячейку памяти, имеем следующий порядок элементов в памяти
А(1, 1), А(1, 2),…, A(l, N), А(2, 1),…, А(2, N),…, А(М, 1),…, А(М, N).
Однородность и упорядоченность элементов двумерного массива позволяют для вычисления адреса элемента массива использовать выражение [18]:
Адрес(А(1, J)) = Адрес(А(1, 1)) + (1-1) * N + (J-1).
Если этим и ограничиться, то для нахождения требуемого элемента в массиве во время выполнения программы понадобится выполнять каждый раз по две операции сложения и вычитания и одну умножения. Однако можно преобразовать выражение к виду:
Адрес (A(I, J)) = (Адрес (А(1, 1)) — N— 1) + (I*N + J) . (4.1)
В (4.1) первое слагаемое является константой и его можно вычислять один раз и теперь для вычисления адреса A(I, J) необходимо выполнить уже одно умножение и два сложения.
Второй метод представления массива состоит в том, что помимо памяти для значений элементов массива, транслятор строит специальный описатель массива — информационный вектор массива (ИВМ). ИВМ содержит информацию, позволяющую, с одной стороны, свести до минимума число машинных команд для вычисления адреса нужного элемента, а с другой, обеспечивает возможность использования в языке динамических массивов.
Структуру ИВМ, назначение его полей и правила его построения в варианте массивов любой размерности рассмотрим на примере ИВМ арифметических данных, транслятора ПЛ/1-0. ИВМ здесь имеет размер V = (2*n+l)*4 байт, n — размерность массива. Адрес элемента массива вычисляется с использованием данных, хранящихся в ИВМ по формуле:
![]()
где ij — значение j-ro индекса, Аф — фиктивный адрес, это адрес элемента массива с нулевыми значениями индексов (такого элемента в массиве может и не быть). Вычисление Аф ведется по формуле
![]()
где ![]() – нижняя граница j-го индекса.
– нижняя граница j-го индекса.
Смещение Сф вычисляется по формуле:
![]()
Множители Мj определяют разность адресов двух элементов массива, j-e индексы которых отличаются на единицу, а все остальные одинаковы:
![]()
При размещении массива в памяти по строкам (в ПЛ/1-0 именно так и хранятся массивы), значение множителя Мn совпадает со значением длины элемента массива, значения же остальных множителей вычисляются по формуле:
![]()
где ![]() – верхняя граница j-го индекса, j = 2, 3,…,n.
– верхняя граница j-го индекса, j = 2, 3,…,n.
Вычисленные таким образом значения множителей Мj хранятся в ИВМ. Структура ИВМ арифметических данных транслятора ПЛ/1-0 показана на рис. 4.3. Отметим, что от того, когда выполнять вычисление параметров ИВМ — во время трансляции или во время выполнения программы, зависит возможность включения в язык в качестве структуры данных, так называемых, динамических массивов. В ПЛ/1 это выполняется во время выполнения программы, поэтому допустимы и динамические массивы.
|
Сф |
||
|
М1 |
||
|
|
|
|
|
… |
||
|
Mn |
||
|
|
|
|
Рис. 4.3. Информационный вектор массива.
Таким образом, типы данных исходной программы в процессе трансляции должны быть отображены на типы данных машины. Представление значений типа данного в памяти машины должно обеспечивать эффективное выполнение операций, применяемых при обработке данных этого типа. Поэтому для простых типов данных (целые и вещественные числа, литеры и т.д.) применяется, как правило, прямое аппаратное представление. Для таких представлений операции над типами имеют прямые аналоги машинных команд. Для сложных типов (массивы, структуры, записи и т.д.) помимо памяти под элементы этих типов транслятор создает вспомогательные структуры — дескрипторы (информационные вектора), указатели, с помощью которых и обеспечивается эффективный доступ к значениям элементов сложного типа. С основными способами машинного представления структурных типов данных языков программирования можно познакомится в работах [11, 18].
Программа на выходе транслятора в общем случае состоит из двух областей: области команд и области данных. В области команд размещаются команды объектной программы, размер этой области вычисляется во время трансляции и равен сумме длин команд объектного хода. Физическая память для области команд выделяется обычно во время загрузки программы загрузчиком (редактором связей, компоновщиком).
С областью данных дела обстоят несколько по-другому. Так как в программе есть данные с ограниченным временем существования, например, локальные и промежуточные переменные вложенных блоков и процедур, то нет смысла закреплять за этими переменными ячейки памяти в области данных на все время выполнения
программы. И, наоборот, за глобальными и промежуточными переменными основной программы необходимо закрепить память на все время выполнения программы. В языке программирования могут быть также средства, которые позволяют программисту самому выделять и освобождать память для переменных. С этих позиций всю область данных объектной программы целесообразно разделить:
· на статическую область — эта область имеет постоянное число ячеек памяти, которые закрепляются за элементами данных, имеющих статус глобальных и не локальных переменных, на все время выполнения программы;
· автоматическую область — размер этой области изменяется в ходе выполнения программы, изменяется и закрепление ячеек памяти за элементами данных для локальных переменных, однако структура и логика изменения области для этих переменных однозначно определяется структурой вложенности блоков и процедур, которая известна в период трансляции;
· динамическую область — управление выделением и освобождением памяти для данных занимается программист, логика изменения динамической области транслятору не известна.
В языках программирования область действия переменной в процедуре (блоке) определяется в контексте описания процедуры, а не в контексте ее вызова. Это обеспечивает возможность управления памятью в автоматической области с использованием информации о вложенности блоков и процедур, получаемой в ходе синтаксического анализа.
Основная идея этого управления: автоматическая область памяти рассматривается как стек, на который в период трансляции накладывается логическая структура, отражающая вложенность блоков и процедур. При этом для внутренних переменных блока отводится участок стека — рамка и переменные в блоке адресуются в виде пары (<номер рамки>, <смещение>), где номер рамки соответствует номеру блока (процедуры) при статической их вложенности, смещение — адресу переменной относительно начала рамки. Во время генерации машинных команд эта пара хранится в таблице идентификаторов и переводится в действительный адрес переменной, т.е. в пару (<регистр адреса базы>, <смещение>), где <регистр адреса базы> — это обычно индексный регистр, в который при входе в блок во время выполнения программы помещается адрес первой ячейки памяти, выделенной данной рамке. А так как динамика вызовов процедур в ходе выполнения программы не может нарушить структуру статической их вложенности, то адрес начала текущей рамки можно всегда определить, если известен адрес начала и размер объемлющей рамки. Поэтому в период выполнения программы необходимо хранить информацию о статической вложенности процедур (блоков). Реализуется это с помощью малого стека — дисплея, при этом в стеке находятся адреса начала рамок блоков в последовательности их вызовов. И при входе в блок (процедуру) адрес начала рамки активного блока помещается в вершину дисплея, а при выходе — выталкивается из него.
В объектной программе дисплей может быть реализован различными способами: для него может быть выделен отдельный стек, но его можно хранить и непосредственно в связанной с ним области данных процедуры (блока).
Помимо областей для хранения значений локальных и промежуточных переменных транслятор должен выделить в области данных процедуры ячейки:
· для области сохранения состояния вычислительного процесса процедуры (здесь запоминаются содержимое регистров и адрес возврата в вызывающую область);
· области для приема значений фактических параметров (или их адресов).
Область данных процедуры (блока) имеет фиксированную длину, определяемую во время трансляции. Порядок выделения ячеек для простых переменных, информационных векторов и промежуточных переменных не имеет значения. Самый простой способ — это распределять память, следуя порядку описаний в блоке (процедуре).
Если в языке программирования нельзя использовать динамические массивы, то размер области данных процедуры известен во время трансляции и функция управления памятью во время выполнения программы сводится к управлению дисплеем. Если же динамические массивы допустимы в языке, то ситуация несколько усложняется. В этом случае размер рамки стека для хранения элементов массива во время трансляции не известен. Решается эта проблема достаточно просто: выделяют статическую память для процедуры (блока) в начале каждой рамки, а во время выполнения — динамическую память для элементов массива в конце рамки.
На рис. 4.4 и 4.5 показан фрагмент блочной программы и содержимое центрального стека и дисплея в момент вызова процедуры D.
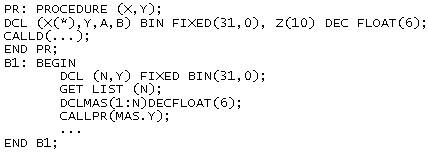
Рис. 4.4. Фрагмент блочной программы
Таким образом, область данных процедуры логически состоит из двух частей: статической и динамической. В статической части память распределяется во время трансляции и включает следующие основные области:
· область сохранения состояния вычислительного процесса;
· область для локально описанных простых переменных и для информационных векторов локальных структур данных;
· область для промежуточных переменных;
· область для хранения адресов фактических параметров процедуры.
В динамической части области данных процедуры выделяется память для хранения элементов динамических массивов. Для этого при входе в процедуру во время выполнения программы вызывается подпрограмма размещения массива, которая вычисляет всю необходимую информацию и заносит ее в информационный вектор, а затем занимает в стеке нужное число ячеек для элементов массива и заносит вычисленный адрес текущей рамки на вершину дисплея.
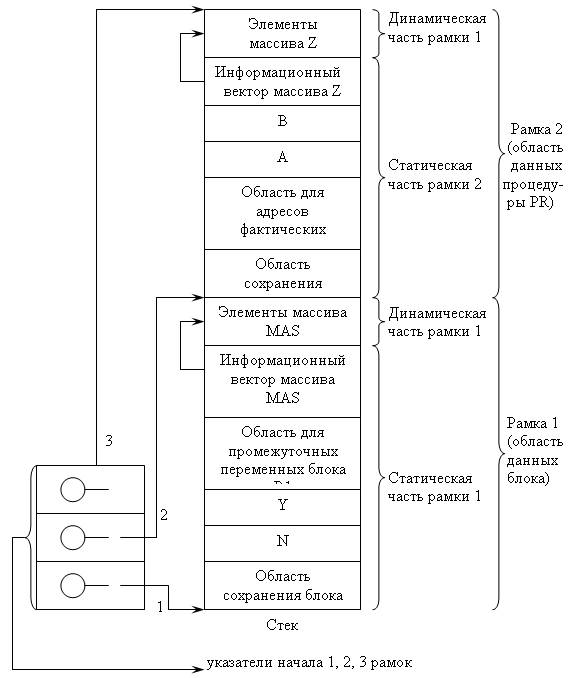
Рис. 4.5. Содержимое центрального стека и дисплея в момент вызова процедуры D
Память для динамических структур данных, определяемых программистом, выделяется обычно в пределах единого сегмента памяти, называемого кучей. Куча — это блок памяти, части которого выделяются и освобождаются некоторым способом, не подчиняющимся какой-либо структуре. В этом случае возникают проблемы, связанные с выделением, утилизацией и повторным использованием памяти из кучи. Единого метода управления кучей не существует. На практике используются частные приемы, такие как счетчики ссылок, сборка мусора [12] и другие.