Многозначность интерпретации — обычное явление при понимании естественных языков и распознавании изображений и речи.
При понимании естественных языков большими проблемами становятся многозначность смысла слов, многозначность их подчиненности, многозначность местоимений в контексте и т. п. Как правило, устранение многозначности обеспечивается за счет более широкого контекста и семантических ограничений. При обработке изображений часто многозначна интерпретация элементов изображения (контуры, области и т. п.). В общем случае устранить многозначность помогают более широкие пространственные отношения и другие способы. Метод релаксации — это метод систематического устранения многозначности при интерпретации изображений с помощью циклических операций. Этот метод объяснен ниже, в качестве знаний в нем используются локальные ограничения. Существуют дискретный и вероятностный методы релаксации.
Метод релаксации
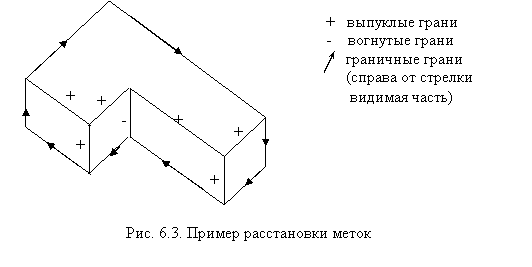
На рис. 6.3 приведен пример расстановки меток, указывающих интерпретацию физического смысла линий (граней) многогранника.
 |
Собственно метод релаксации — это метод численного решения дифференциальных уравнений в частных производных, но в середине 70-х гг. его стали использовать также для обработки и анализа изображений. Распространив его на локальные ограничения, можно устранить многозначность интерпретации изображения. Этот метод можно использовать не только в случае стандартного представления знаний (правила и т. п.) и механизма выводов, как в инженерии знаний, но и в других случаях, где необходимо устранение многозначности. Рассмотрим дискретный метод релаксации на примере интерпретации контурных рисунков.
Будем рассматривать выделение граней и получение контурного рисунка из черно-белого изображения многогранника, например из детского строительного набора. Одним из этапов распознавания предмета является интерпретация физического смысла линий. Для каждой грани при этом можно указать, что она выпукла (помечена знаком «+»), вогнута (помечена знаком «—») или является граничной (помечена знаком →,
справа от стрелки — видимая поверхность)(рис. 6.3). Выберем самый простой случай и получим контуры прямоугольного параллелепипеда. Если ограничиться многогранниками, в каждой вершине которых сходятся ровно три стороны, то можно точно перечислить все возможные физические типы вершин. На рис. 6.4, а показаны все случаи локальной интерпретации вершин. При локальном взгляде на вершину ее интерпретация многозначна, но ограниченна. Устранить многозначность можно путем согласования с соседними вершинами.
Если в этом примере интерпретации контура рассмотреть две соседние вершины, связанные гранью, то эта грань непременно должна иметь одну и ту же интерпретацию (метку). Следовательно, при интерпретации соседних вершин нужно отбрасывать интерпретацию, не удовлетворяющую этому условию. Проделаем это для всех соседних вершин (как параллельную обработку). Подобную операцию называют фильтрацией, на рис. 6.4, б представлена возможная интерпретация вершин после однократной фильт-рации.
Число кандидатур на интерпретацию вершин сократилось, поэтому можно вновь повторить фильтрацию, исключая интерпретации вершин, которые дают разные грани между соседними вершинами. На рис. 6.4, в — интерпретация вершин после трехкратного применения фильтрации, больше число кандидатур на интерпретацию сократить не удается, т. е. нельзя получить однозначный ответ. Итак, мы пришли к четырем (правильным) интерпретациям, указанным на рис. 6.4, г. Выше дан конкретный пример дискретного метода релаксации — метода, который предусматривает устранение многозначности при локальных ограничениях и выбор интерпретации через согласование ограничений в целом.
Модель доски объявлений
Рассмотрим модель доски объявлений на примере работы системы понимания речи — HEARSAY-II, разработанной в Университете Карнеги — Меллона. Примерно с вероятностью 90 % она может понимать связную речь в ограниченном диапазоне среди 1011 слов, относящихся к информатике и поиску литературы. Например, она может понимать вопросы типа
«В каких рефератах есть ссылки на теорию вычислений?»,
«Есть ли ссылки на Фейгенбаума и Фельдмана?»
и интерпретировать их до уровня создания команд для поиска в библиографической базе данных.
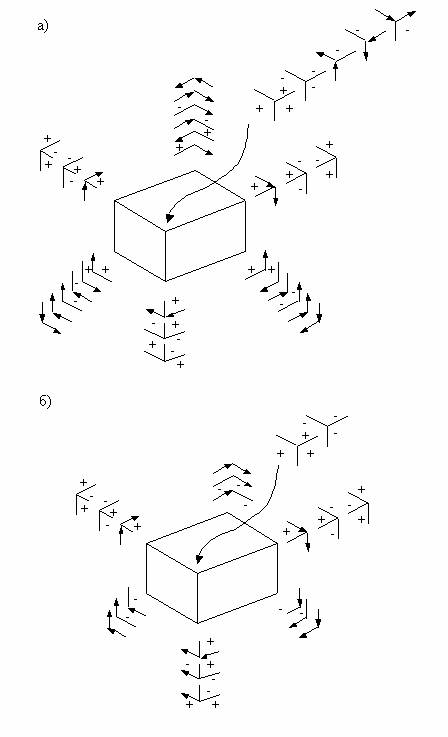 Рис. 6.4. Пример релаксации при интерпретации контурных рисунков
Рис. 6.4. Пример релаксации при интерпретации контурных рисунков
(начало): а – возможные локальные интерпретации вершин;
б – возможные интерпретации вершин после однократной фильтрации
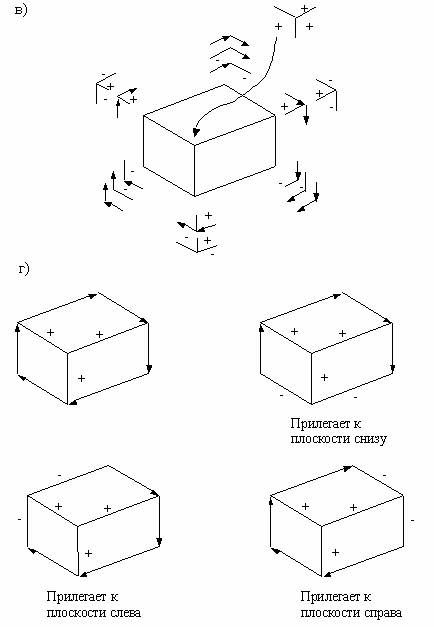
Рис. 6.4. Пример метода релаксации при интерпретации контурных рисунков
(продолжение): в – возможные интерпретации вершин после трехкратной
фильтрации; г – четыре возможные интерпретации
Предусмотрено семь уровней понимания от акустических параметров звуковых волн до понимания смысла вопроса (рис. 6.5). На этом же рисунке указаны необходимые для этого знания, управление знаниями ведется через отдельные источники знаний (форма представления знаний — модули (типа правил), состоящие из пар (блок условия—блок действия). Понимание осуществляется на основе данных низшего уровня с переходом к интерпретации на следующий уровень; интерпретация не всегда однозначна и обычно генерируются несколько гипотез. Каждая гипотеза оценивается с использованием информации верхнего уровня, в результате остается одна гипотеза, которая считается правильной. К гипотезам добавляется оценка (число от 0 до 100), указывающая их достоверность, но эта оценка действует ad hoc. В конце концов, выбирая наиболее достоверную гипотезу на уровне фразы, извлекается смысл вопроса для поиска литературы.
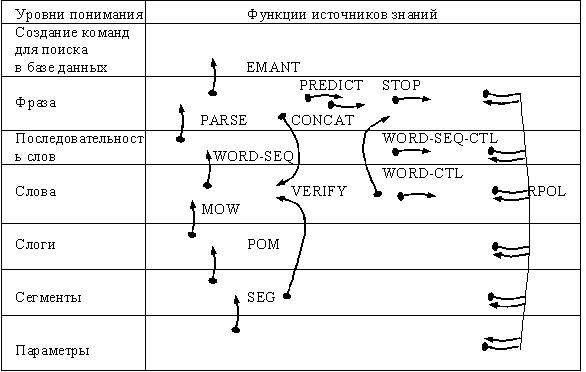
Рис. 6.5. Структура знаний в системе понимания речи HEARSAY-II (знания распределены по источникам знаний, знак указывает место сопоставления данных в условиях, конец стрелки — место занесения действия). Источники знаний — набор модулей типа «условие—действие»
указывает место сопоставления данных в условиях, конец стрелки — место занесения действия). Источники знаний — набор модулей типа «условие—действие»
На рис. 6.5:
SEQ — преобразует речевые сигналы в дискретную форму, измеряет
параметры, образует сегменты.
РОМ — на основе сегментов создает гипотезу о слогах.
MOW — на основе слогов создает гипотезы о простых словах.
WORU-CTL — управляет числом гипотез, созданных модулем MOW.
WORD-SEQ — на основе гипотез о словах и грамматических правил создает
гипотезы о последовательности слов.
WORD-SEQ-CTL — управляет числом гипотез, созданных модулем WORD-
SEQ
PARSE — делает грамматический разбор последовательности слов, если все
верно, создает гипотезы о фразе.
PREDICT — предсказывает слова, которые предшествуют или следуют за фразой.
VERIFY — оценивает степень соответствия между гипотезой о сегментах и
парой связанных слов.
CONCAT — на основе проверенных пар связанных слов создает гипотезу о
фразе.
RPOL — оценивает степень доверия другим гипотезам на основе информации
в гипотезах, созданных другими источниками.
STOP — оценивает необходимость остановки процесса (закончено ли пред-
ложение?) и выбирает гипотезу, которая считается наиболее верной.
SEOMANT — интерпретирует смысл для системы поиска информации.
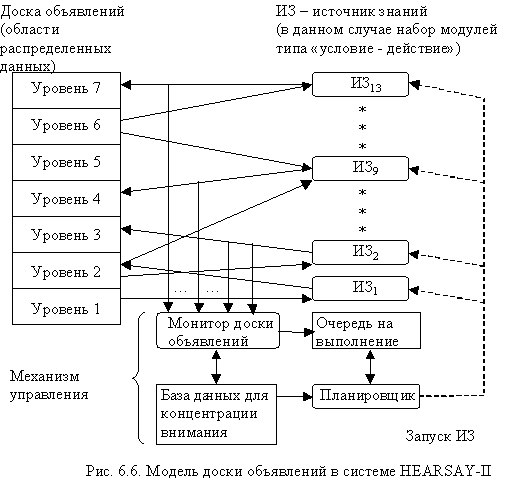 |
Структура системы HEARSAY-II — это модель доски объявлений (рис. 6.6). Она представляет собой распределенную область данных, каждый источник знаний (ИЗ) обращается к соответствующим областям доски объявлений, вносит гипотезы или дает им оценки в других областях.
Эту систему можно рассматривать как распределенную иерархическую высоко- уровневую продукционную систему. В принципе можно считать, что все источники знаний, действуя асинхронно и параллельно, переписывают содержимое доски объявлений, что плохо поддается реализации на последовательных компьютерах. Поэтому предусмотрен механизм управления, планирующий работу так, чтобы в первую очередь действовал источник знаний с высшим приоритетом (такой механизм аналогичен механизму списка заявок в программе AM, рассмотренной в разделе 6.2.). Модель доски объявлений, разработанная в системе HEARSAY-II, в дальнейшем предполагается
реализовать как систему представления универсальных знаний. Она дает хороший эффект для согласованного устранения многозначности и нечеткости, возникающих на каждом этапе процесса понимания и интерпретации, с помощью знаний на различных уровнях.