FineReader – омнифонтовая система оптического распознавания текстов. Это означает, что она позволяет распознавать тексты, набранные практически любыми шрифтами, без предварительного обучения. Особенностью программы FineReader является высокая точность распознавания и малая чувствительность к дефектам печати, что достигается благодаря применению технологии «целостного целенаправленного адаптивного распознавания».
Новая версия системы распознавания текстов, стала еще точнее. Она лучше сохраняет оформление документов сложного дизайна, позволяет распознавать PDF-файлы, поддерживает 177 языков и предоставляет усовершенствованный интерфейс пользователя, который теперь включает многоколоночный WYSIWYG-редактор, имеет настраиваемые панели инструментов и позволяет выполнять печать документов и изображений непосредственно из программы. Помимо усовершенствования интерфейса, в ABBYY FineReader 6.0 повысилась точность распознавания и точность сохранения внешнего оформления и структуры распознаваемого документа. Улучшено качество обработки документов со сложным дизайном: многоколоночного текста, непрямоугольных картинок, цветного фона. Шестая версия программы распознает не просто текст, а документ в целом, включая шрифты, расположение картинок и общую верстку.
Новый продукт поставляется в двух версиях: ABBYY FineReader 6.0 Professional (для использования на отдельно стоящем компьютере) и ABBYY FineReader 6.0 Corporate Edition (для использования в сетевой среде).
Установка и запуск программы
Для установки FineReader используется специальная программа установки, входящая в состав дистрибутива. Всегда производите установку, используя дискету и CD-Rom только из дистрибутива, который вы получили при покупке. Установочные файлы и файлы на CD-Rom записаны в специальном виде, после копирования их на другой носитель программа инсталляции будет работать некорректно.
Опции установки
После того как программа установки проверит систему, наберите свое имя и укажите, куда следует установить ABBYY FineReader. Программа установки отобразит несколько опций установки. Выберите один из вариантов установки:
· «Обычная» (рекомендуется) – устанавливаются все компоненты дистрибутива, в том числе все языки распознавания, язык интерфейса (один) – выбранный при установке;
· «Установка компонентов дистрибутива по выбору» – из предложенного набора компонентов, входящих в дистрибутив, вы можете выбрать только те, которые нужны вам (в том числе доступные языки распознавания).
Внимание! Если вы хотите применять пользовательские словари и эталоны из предыдущей версии программы, не деинсталлируйте ее до инсталляции новой версии. Установив новую версию, вы сможете применять эталоны и словари предыдущей версии.
Главное окно программы FineReader
Работая с программой FineReader, пользователь всегда имеет дело с некоторым пакетом. Пакет – это папка, в которой хранятся изображения и рабочие файлы программы. Каждое отсканированное изображение записывается как отдельная страница пакета. При первом запуске FineReader на экране появляется пакет, созданный программой по умолчанию. Вы можете продолжить работу с пакетом по умолчанию или создать новый пакет.
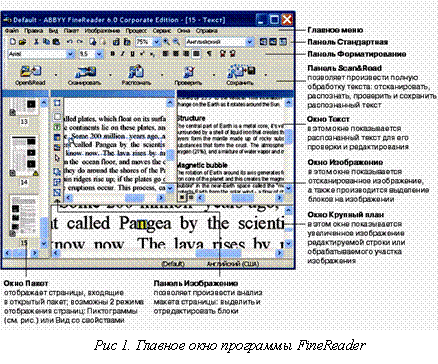
Вверху главного окна FineReader (рис. 1) находится меню системы, под ним – инструментальные панели. В программе их четыре: «Стандартная», «Форматирование», «Изображение» и «Scan&Read».
Панель «Стандартная»
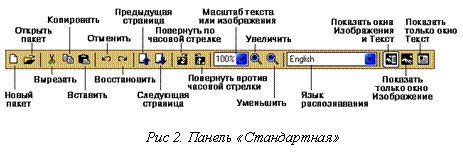
На панели «Стандартная» (рис. 2) находятся кнопки, управляющие работой с файлами и изображением (отмена и повтор действия, перемещение по страницам пакета, очистка и поворот изображения), а также список языков распознавания.
Замечание. Вид окна программы FineReader, точнее количество кнопок на панелях инструментов «Изображение», «Стандартная» и «Форматирование», зависит от разрешения экрана вашего компьютера. Чтобы увидеть все кнопки программы, поменяйте разрешение экрана на более высокое.
Панель «Форматирование»
На панели «Форматирование» (рис. 3) находятся кнопки, позволяющие изменить оформление текста.
Панель «Изображение»
Панель «Изображение» (рис. 4) содержит кнопки, позволяющие производить анализ макета страницы (например, создать и отредактировать блоки), а также кнопки, позволяющие увеличить (уменьшить) масштаб изображения, отредактировать изображение (например, стереть ненужные участки изображения, такие, как подписи или большие участки «мусора»).
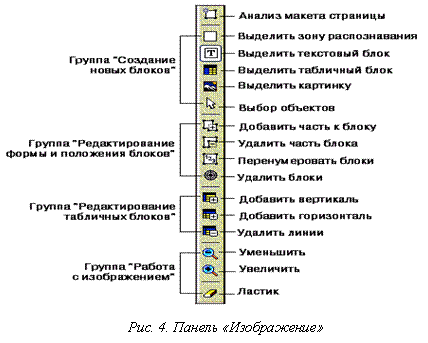
Кнопки, позволяющие создать и отредактировать блоки, можно использовать не только в окне «Изображение», но и в окне «Крупный план».
Панель Scan&Read
Если вы хотите узнать о назначении той или иной кнопки на инструментальной панели, установите на ней курсор мыши. Под кнопкой появится подпись (tooltip), а на информационной панели будет выведено более подробное сообщение о назначении этой кнопки.
Кнопки на панели «Scan&Read» (рис. 5) связаны с базовыми операциями системы: «Сканирование», «Распознавание», «Проверка» и «Сохранение» результатов распознавания. Цифры на кнопках указывают, в каком порядке нужно выполнить действия, чтобы получить электронную версию бумажного документа. Каждое из этих действий можно провести по отдельности или объединить в одно, нажав на кнопку «Мастер Scan&Read». Она позволяет провести полный цикл обработки текста автоматически.
Каждая из кнопок имеет несколько режимов работы. 
Нажав на стрелку справа от кнопки, в открывшемся локальном меню вы можете выбрать один из этих режимов, при этом «информация» об этом отразится на значке кнопки. Для того чтобы повторить ту же операцию для другого изображения, вам достаточно повторно нажать на кнопку.
Настройка инструментальных панелей
FineReader позволяет настраивать инструментальные панели «Изображение», «Стандартная» и «Форматирование»: добавлять и удалять кнопки, осуществляющие доступ ко всем командам программы.
Каждому пункту меню соответствует свой значок. Полный список команд и соответствующих им кнопок приведен в диалоге «Настройка» (меню «Сервис>Настройка»), в списке
Сканирование
FineReader работает со сканерами через TWAIN-интерфейс. Это единый международный стандарт, введенный в 1992 году для унификации взаимодействия устройств для ввода изображений в компьютер (например, сканера) с внешними приложениями. При этом возможно два варианта взаимодействия программы со сканерами через TWAIN-драйвер:
· через интерфейс FineReader: в этом случае для настройки опций сканирования используется диалог программы FineReader Настройки сканера;
· через интерфейс TWAIN-драйвера сканера: для настройки опций сканирования используется диалог TWAIN-драйвера сканера.
Преимущества одного режима перед другим:
· в режиме «Использовать интерфейс TWAIN-драйвера сканера», как правило, доступна функция предварительного просмотра изображения (preview), позволяющая точно задать размеры сканируемой области, подобрать яркость, тут же контролируя результаты этих изменений. К сожалению, диалог TWAIN-драйвера сканера у каждого сканера выглядит по-своему, в большинстве случаев все надписи на английском языке.Вид этого окна и смысл опций описан в документации, прилагаемой к сканеру;
· в режиме «Использовать интерфейс FineReader» доступны такие опции, как возможность сканирования в цикле на сканерах без автоподатчика, сохранение опцийсканирования в отдельный файл «Шаблон пакета (*.fbt)» и возможность использования этих опций в других пакетах.
Установка параметров сканирования
Качество распознавания во многом зависит от того, насколько хорошее изображение получено при сканировании. Качество изображения регулируется установкой основных параметров сканирования. Основными параметрами сканирования являются:
· «Тип изображения» – серый (256 градаций). Сканирование в сером является оптимальным режимом для системы распознавания. В случае сканирования в сером режиме осуществляется автоматический подбор яркости. Черно-белый тип изображения обеспечивает более высокую скорость сканирования, но при этом теряется часть информации о буквах, что может привести к ухудшению качества распознавания на документах среднего и низкого качества печати. Если вы хотите, чтобы содержащиеся в документе цветные элементы (картинки, цветные буквы и цветной фон) были переданы в электронный документ с сохранением цвета, необходимо выбрать цветной тип изображения. В других случаях используйте серый тип изображения;
· «Разрешение» – используйте 300 dpi для обычных текстов (размер шрифта 10 и более пунктов) и 400 – 600 dpi для текстов, набранных мелким шрифтом (9 и менее пунктов);
· «Яркость» – в большинстве случаев подходит среднее значение яркости – 50 %. На некоторых документах при сканировании в черно-белом режиме может понадобиться дополнительная настройка яркости.
Чтобы установить параметры сканирования:
¨ при сканировании через TWAIN с использованием интерфейса FineReader: в меню «Сервис» выберите пункт «Настройки сканера» и в открывшемся диалоге Настройки сканера установите нужные опции;
¨ при сканировании через TWAIN с использованием интерфейса TWAIN-драйвера сканера для установки параметров сканирования используется диалог вашего сканера, который открывается автоматически при нажатии на кнопку «Сканировать». Опции для установки параметров сканирования могут называться по-разному, в зависимости от модели сканера. Например, яркость может называться «brightness», «threshold», изображаться «солнышком» или черно-белым кружком. Смысл опций описан в документации, прилагаемой к вашему сканеру.
Подбор яркости
Отсканированное изображение должно быть удобочитаемым (просмотрите изображение в окне «Крупный план»):
|
|
– пример хорошего (в смысле распознавания) изображения. |
Если в полученном изображении вы обнаружили множество дефектов (разрывов или склеек букв), то обратитесь к следующей таблице, которая указывает возможные способы устранения этих дефектов:
|
Особенности входного изображения: |
Что сделать: |
|
«разорванные»; светлые, тонкие буквы |
Уменьшить яркость (чтобы изображение стало темнее) Попробовать отсканировать в сером (в этом случае осуществляется автоподбор яркости) |
|
искаженные и залитые; склеенные символы; темные, толстые буквы |
Увеличить яркость (сделатьизображение светлее) Попробовать отсканировать в сером (в этом случае осуществляется автоподбор яркости) |
Чтобы открыть изображение:
¨ нажмите стрелку справа от кнопки «Сканировать» и в локальном меню выберите пункт «Открыть изображение». Внешний вид значка изменится; подпись «Сканировать» поменяется на «Открыть»;
¨ в меню «Файл» выберите пункт «Открыть изображение».
¨ в Windows Explorer: щелкните правой кнопкой мыши на файле с изображением и в локальном меню выберите пункт «Открыть с помощью FineReader». Если на вашем компьютере уже открыт FineReader, изображение будет добавлено в текущий пакет, в противном случае перед добавлением изображения в пакет автоматически запустится FineReader с пакетом, с которым вы работали в последний раз.
¨ в диалоге «Открыть» (Open) выберите одно или несколько изображений. Выбранные изображения появятся в окне «Пакет», и последнее из выбранных изображений откроется в окне «Изображение» и в окне «Крупный план» на экране FineReader, при этом копия изображения помещается в папку пакета. Если вы хотите, чтобы открытые изображения были сразу распознаны, воспользуйтесь режимом «Открыть и распознать».
Добавление в пакет изображений со сдвоенными страницами
При сканировании книг удобнее отсканировать две страницы (разворот) сразу. При этом для повышения качества распознавания такие изображения следует разделить на два, чтобы каждой странице соответствовала отдельная страница пакета (анализ и распознавание осуществляется для каждой страницы по отдельности, исправляется перекос строк).
Для этого перед сканированием или добавлением в пакет сдвоенных страниц на закладке «Сканирование/Открытие» (меню «Сервис>Опции») отметьте опцию «Делить разворот книги». В этом случае книжный разворот (сдвоенные страницы) будет представлен двумя страницами пакета. Подробнее о пакете см. в меню «Общая информация по работе с пакетом».
Если книжный разворот (сдвоенные страницы) был разделен на две страницы неверно, то снимите отметку с опции «Делить разворот книги», заново отсканируйте или добавьте в пакет изображение с книжным разворотом и попробуйте разделить его в диалоге «Разбить изображение» (меню «Изображение>Разбить изображение») вручную.
Проверка и корректирование полученного изображения Очистить от мусора
Распознаваемое изображение может быть сильно «замусорено», т.е. содержать много лишних точек, возникших в результате сканирования документов среднего или плохого качества. Точки, близко расположенные к контурам букв, могут отрицательно сказаться на качестве распознанного текста. Чтобы уменьшить количество лишних точек, можно воспользоваться опцией «Очистить от мусора». Для этого в меню «Изображение» выберите пункт «Очистить изображение от мусора».
Если вы хотите очистить от «мусора» отдельный блок, то в меню «Изображение» выберите пункт «Очистить блок от мусора».
Если исходный текст был очень светлым или в исходном тексте использовался очень тонкий шрифт, то применение функции «Очистить изображение от мусора» может привести к исчезновению точек, запятых или тонких элементов букв, что ухудшит качество распознавания. Если вы сканируете или открываете «замусоренные» изображения, то перед добавлением в пакет таких изображений в группе «Обработка изображений» на закладке «Сканирование/Открытие» (меню «Сервис>Опции») отметьте пункт «Очистить изображение от мусора».
Инвертировать изображение
Некоторые сканеры инвертируют изображения при сканировании (черный цвет переводят в белый, а белый в черный). Чтобы получить стандартное представление документа (черный шрифт на белом фоне) в меню «Изображение» выберите пункт «Инвертировать».
Если вы сканируете или открываете инвертированные изображения, то перед добавлением в пакет таких изображений в группе «Обработка изображений» на закладке «Сканирование/Открытие» (меню «Сервис>Опции») отметьте пункт «Инвертировать».
Повернуть или зеркально отразить изображение
При распознавании изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз, и строки должны быть горизонтальными. По умолчанию программа при распознавании определяет и корректирует ориентацию изображения автоматически. Если ориентация изображения была определена ошибочно, то на закладке «Сканирование/Открытие» снимите отметку с пункта «Определять ориентацию страницы (в процессе распознавания)» и поверните изображение вручную.
Чтобы повернуть изображение:
¨ на 90 градусов вправо, нажмите кнопку ![]() или выберите в меню «Изображение» пункт «Повернуть по часовой стрелке»;
или выберите в меню «Изображение» пункт «Повернуть по часовой стрелке»;
¨ на 90 градусов влево, нажмите кнопку ![]() или выберите в меню «Изображение» пункт «Повернуть против часовой стрелки»;
или выберите в меню «Изображение» пункт «Повернуть против часовой стрелки»;
¨ на 180 градусов – выберите в меню «Изображение» пункт «Повернуть на 180 градусов».
Чтобы зеркально отразить изображение относительно:
¨ горизонтальной прямой, выберите в меню «Изображение» пункт «Зеркально отразить относительно горизонтали»;
¨ вертикальной прямой, выберите в меню «Изображение» пункт «Зеркально отразить относительно вертикали».
Стереть участок изображения
Если вы хотите исключить какой-то участок текста из распознавания или у вас на изображении имеются большие участки мусора, то вы можете стереть такие участки. Для этого выберите инструмент ![]() (на панели в окне «Изображение») и, нажав на левую кнопку мыши, выделите участок изображения, который вы хотите удалить. Отпустите кнопку, выделенная часть изображения будет удалена.
(на панели в окне «Изображение») и, нажав на левую кнопку мыши, выделите участок изображения, который вы хотите удалить. Отпустите кнопку, выделенная часть изображения будет удалена.
Увеличить (уменьшить) масштаб изображения
На панели «Изображение» (в окне «Изображение») выберите инструмент ![]() и щелкните мышью на изображении.Изображение увеличится (уменьшится) в два раза.
и щелкните мышью на изображении.Изображение увеличится (уменьшится) в два раза.
Щелкните правой кнопкой мыши на изображение и в локальном меню выберите пункт «Масштаб» и нужный вам масштаб.
Нумерация страниц при добавлении в пакет
По умолчанию каждой сканируемой странице присваивается номер на единицу больший номера последнего изображения в пакете. Вы можете задать номер добавляемой страницы и вручную (например, вам нужно сохранить исходную нумерацию страниц или вы сканируете стопку сортированных по порядку страниц). Для этого на закладке «Сканирование/Открытие» (меню «Сервис>Опции») отметьте пункт «Запрашивать номер страниц при добавлении в пакет».
При сканировании стопки двусторонних сортированных по порядку страниц:
¨ отметьте пункт «Запрашивать номер перед добавлением в пакет» на закладке «Сканирование/Открытие» («Сервис>Опции»);
¨ в диалоге «Номер страницы» укажите номер страницы, с которой начинается сканирование и выберите опцию «Через одну» в поле «Нумерация страниц». Выберите способ нумерации страниц: по возрастанию или по убыванию. Возрастание или убывание зависит, например, от того, как вы кладете стопку в автоподатчик – находятся ли меньшие или большие номера наверху.
Анализ макета страницы
Прежде чем приступить к распознаванию, программа должна знать, какие участки изображения надо распознавать. Для этого проводится анализ макета страницы, во время которого выделяются блоки с текстом, картинки, таблицы и штрих-коды.
Рассмотрим, когда может потребоваться провести ручной анализ макета страницы, какие типы блоков бывают, как можно отредактировать полученные в результате автоматического анализа блоки, а также как можно упростить процесс анализа, используя шаблоны блоков.
Типы блоков
Блоки – это заключенные в рамку участки изображения. Блоки выделяют для того, чтобы указать системе, какие участки отсканированной страницы надо распознавать и в каком порядке. Также по ним воспроизводится исходное оформление страницы. Блоки разных типов имеют различные цвета рамок. Вы можете изменить цвета рамок блоков на закладке «Вид» диалога «Опции» (меню «Сервис>Опции») в группе «Объекты». В поле «Объект» выберите нужный тип блока, а в поле «Цвет» – требуемый цвет.
При обработке изображений выделяют блоки следующих типов:
· «Зона Распознавания» – блок используется для распознавания и автоматического анализа части изображения. После нажатия на кнопку «Распознать» выделенный блок автоматически анализируется и распознается;
· «Текст» – блок используется для обозначения текста. Он должен содержать только одноколоночный текст. Если внутри текста содержатся картинки, выделите их в отдельные блоки;
· «Таблица» – этот блок используется для обозначения таблиц или текста, имеющего табличную структуру. При распознавании программа разбивает данный блок на строки и столбцы и формирует табличную структуру. В выходном тексте данный блок передается таблицей. Вы можете выделить и отредактировать таблицу вручную;
· «Картинка» – этот блок используется для обозначения картинок. Он может содержать картинку или любую другую часть текста, которую вы хотите передать в распознанный текст в качестве картинки;
· «Штрих-код» (только в версии Corporate Edition) – этот блок используется для распознавания штрих-кодов. То есть, если ваш документ содержит штрих-код и вы хотите передать его не картинкой, а перевести его в последовательность букв и цифр, то выделите штрих-код в отдельный блок и присвойте ему тип «Штрих-код». По умолчанию опция, позволяющая искать и распознавать штрих-коды, отключена. Чтобы подключить ее, отметьте пункт «Искать штрих-коды» на закладке «Распознавание» (меню «Сервис>Опции»).
Тип страницы
Для большинства изображений расположение текста на странице определяется автоматически, чему соответствует значение «Авто» на закладке «Распознавание» в группе «Тип страницы» (меню «Сервис>Опции»), устанавливаемое системой по умолчанию. В некоторых случаях может потребоваться установить значение типа страницы вручную. Для этого на закладке «Распознавание» диалога «Опции» (меню «Сервис>Опции») в группе «Тип страницы» выберите нужный вам пункт:
· «Автоматическое определение» – указывает, что расположение текста на странице определяется автоматически. Это значение устанавливается системой по умолчанию; подходит для распознавания всех видов текстов, в том числе многоколоночного текста, текста с таблицами и картинками;
· «Одна колонка» – указывает, что текст на странице напечатан в одну колонку. Эта опция используется в случае, если автоматическое определение ошибочно сегментировало страницу как многоколоночный текст;
· «Форматированный пробелами текст» – указывает, что текст на странице расположен в одну колонку и напечатан моноширинным шрифтом одного размера. В распознанном тексте сохраняется деление на строки; отступы от левого края передаются пробелами; каждая строка выделяется в отдельный абзац, и расстояния между абзацами передаются пустыми строками. Используется, например, для распознавания распечаток текстов программ.
Опции анализа таблиц
В большинстве случаев программа делит таблицу на строки и столбцы автоматически. Дополнительная настройка опций анализа таблиц устанавливается на закладке «Распознавание» в группе «Таблицы». Эти опции рекомендуется использовать, если:
ü в результате автоматического анализа макета страницы таблица была выделена и разделена на строки и столбцы неверно;
ü документ содержит много однотипных таблиц, для которых известна дополнительная информация (например, таблица не содержит объединенных ячеек или таблица состоит из ячеек, текст в которых расположен в одну строку).
Ручной анализ таблицы
Если в результате автоматического анализа таблицы разделение на строки и столбцы произошло неверно, прежде чем анализировать таблицу вручную заново, попробуйте сначала отредактировать результаты автоматического анализа.
Пользовательские языки и группы языков
Вы можете использовать не только предопределенные языки и группы языков, но и создать новый язык или объединить существующие языки в новую группу и при распознавании подключить именно их.
Когда надо создавать новый язык:
¨ для подключения пользовательского словаря. Например, необходимо распознать русский текст, содержащий аббревиатуры. Вы можете создать словарь аббревиатур и подключить его к пользовательскому языку. На основе русского языка с подключенным системным словарем и языка, созданного вами с подключенным словарем аббревиатур, вы можете создать группу для дальнейшего ее использования при распознавании ваших текстов;
¨ для распознавания документов специального вида.
Создать язык или группу языков можно из диалога «Редактор языков» (меню «Сервис» пункт «Редактор языков»).
Проверка распознанного текста
Неуверенно распознанные символы и слова, которых нет в словаре, выделяются различными цветами. По умолчанию для выделения неуверенно распознанных символов используется голубой, для несловарных слов – розовый. Чтобы изменить цвета на закладке «Вид» (меню «Сервис>Опции»), в поле «Объект» выберите пункт «Неуверенно распознанный символ» («Несловарное слово») и в поле «Цвет» – цвет подсветки.
Чтобы проверить результаты распознавания:
¨ нажмите кнопку «Проверить» на панели «Scan&Read» (или выберите пункт «Проверка» в меню «Сервис»);
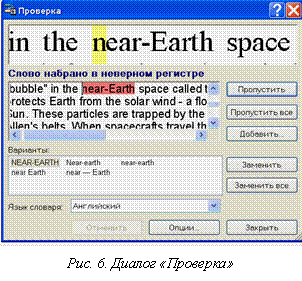
¨ откроется диалог «Проверка» (рис. 6).
Общая информация по сохранению распознанного текста
Вы можете сохранить:
· распознанный текст, используя «Мастер сохранения результатов».
· открытую страницу или выделенные в окне «Пакет» страницы в файл или во внешнее приложение.
· все страницы пакета в файл или во внешнее приложение.
· изображение страницы.
Кнопка «Сохранить» позволяет передать результаты распознавания в выбранное приложение или сохранить их в файл.Внешний вид значка меняется в зависимости от выбранного режима сохранения; подпись «Сохранить» меняется на название выбранного приложения.
Чтобы сохранить распознанный текст нажмите стрелку справа от кнопки «Сохранить» и в локальном меню выберите необходимый пункт. При сохранении нескольких страниц сначала выделите их в окне «Пакет».
После того как вы экспортировали распознанный текст в выбранное вами приложение, отправили его по электронной почте, передали в буфер или сохранили в файл, «информация» об этом действии отразится на значке кнопки «Сохранить». Поэтому для того, чтобы повторить ту же операцию для другого изображения, вам достаточно нажать на этот значок.